 (Wei, Haghtalab and Steinhardt, 2023)
(Wei, Haghtalab and Steinhardt, 2023)In the winter of 25/26 I set out to develop a Universal and Transferable Jailbreak as part of my masters dissertation on offensive techniques against frontier models. 3 months, 100 pages, and 18,252 words (38,000 words total) later, I succeeded.
A jailbreak is a vulnerability in large language models whereby one overrides or overcomes safety alignment to trick or coerce the model into returning dangerous/harmful responses that it would normally refuse to return. Jailbreaks work by hijacking the model’s original goals to force compliance. This works because models are trained to be Helpful; safety alignment is a secondary goal. More specifically, dangerous/harmful responses are returned when the model suffers from Competing Objectives - model capabilities and objectives, such as reasoning and instruction following, conflict with safety training; Mismatched Generalization - edge cases where the massive corpus of training data includes elements that later safety training fails to account for; or poor Adversarial Robustness - even with strictly labeled data and robust safety training, small bespoke perturbations can mask adversarial intent and bypass defensive safeguards.
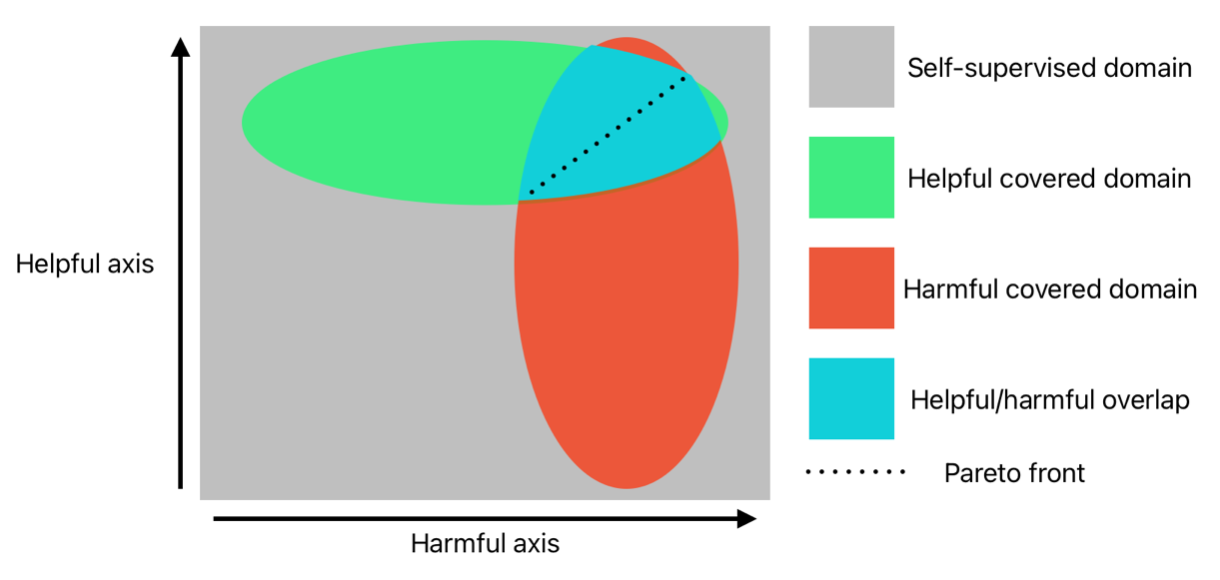
One can think of model responses as falling into one of two domains: Helpful, where the model attempts to ‘land’ its reasoning and readily responds; and Harmful, where the model’s safety training has labeled something as dangerous/harmful and thus provokes a refusal. The key to an effective jailbreak is to provoke a model response that falls within the intersection, i.e. the set of responses that are both Helpful and Harmful. Jailbreaks exploit these overlaps where alignment fails to adequately generalize, competing objectives favor helpfulness maximization, or where subtle perturbations to inputs result in the failure of adversarial robustness training. Mixed attacks using combinations of these techniques with novel methods have the best performance.
(Wei, Haghtalab and Steinhardt, 2023)
The most effective jailbreaking technique is to surgically remove the model’s refusal mechanism, i.e. to entirely undo model safety training. This is called Abliteration and, being that it requires access to model weights, is restricted to open-weight model. This involves identifying and ablating (removing) a low-dimensional refusal direction in residual stream activations, i.e. the safety-aligned behaviors (vectors in n-dimensional space) are identified and refusal activations are replaced with activations orthogonal (or opposite) to such vectors, rigidly and forcefully preventing the model from refusing harmful/dangerous requests. While exceptionally effective (~100% ASR), it incurs a trade-off: such tinkering often leads to slight degradation in model capabilities, with poor or overly excessive abliteration exacerbating this degradation. While manual abliteration is technically challenging, requiring a) collecting contrasting prompt pairs; b) extracting activations at the appropriate layers and token positions; c) computing the refusal direction via various methods; and d) applying precise weight orthogonalization or direction ablation across the model, open source tools such as Heretic automate the entire process, producing jailbroken models in hours, massively reducing the barriers to entry, democratizing jailbreaking of open-weight models.
The most popular jailbreaks have two attributes that make them truly effective: Universality, i.e. the ability for the jailbreak to work on any arbitrary input; and Transferability, i.e. the ability for the jailbreak to work against any model. One of the first examples was DAN (“Do Anything Now”), which, as the name suggests, ordered the model to fully comply with user wishes. More recent examples directly exploit model safety training, such as the ‘LGBTQIA+’ or ‘Jewish Identity’ jailbreaks, whereby the model refusal is reframed as being discriminatory against protected groups, edge cases that force the model to compete between the objectives of anti-bias and harm prevention and thus provoking the desired harmful response. These are jailbreaks which work effectively across any model for an arbitrary input. While effective, such techniques have certain signatures, such as specific strings or behaviors, which make them susceptible to adversarial robustness training, rendering them ineffective for the next iteration of models. Techniques that are more resistant to adversarial robustness training, such as GCG or other highly specified automated attacks, suffer from the same problem as abliteration: it requires access to model weights, i.e. it only works against open-weight models.
Efforts have been made to map AI attack surfaces and isolate individual attack vectors. Modeled on the renowned MITRE ATT&CK framework, MITRE ATLAS maps adversary tactics and techniques against AI systems, with recommended mitigations. Jailbreaking is categorized as just one of ~170 techniques attackers use to abuse AI systems (AML.T0054), which outlines several common strategies such as instruction overrides (e.g. DAN) and roleplay (e.g. Jewish Identity). This specificity allows MITRE to separate the act of jailbreaking a model from closely related techniques such as extracting the system prompt (AML.T0056) or data leakage (AML.T0057). See my presentation at BSIDES LDN 25 for more info.
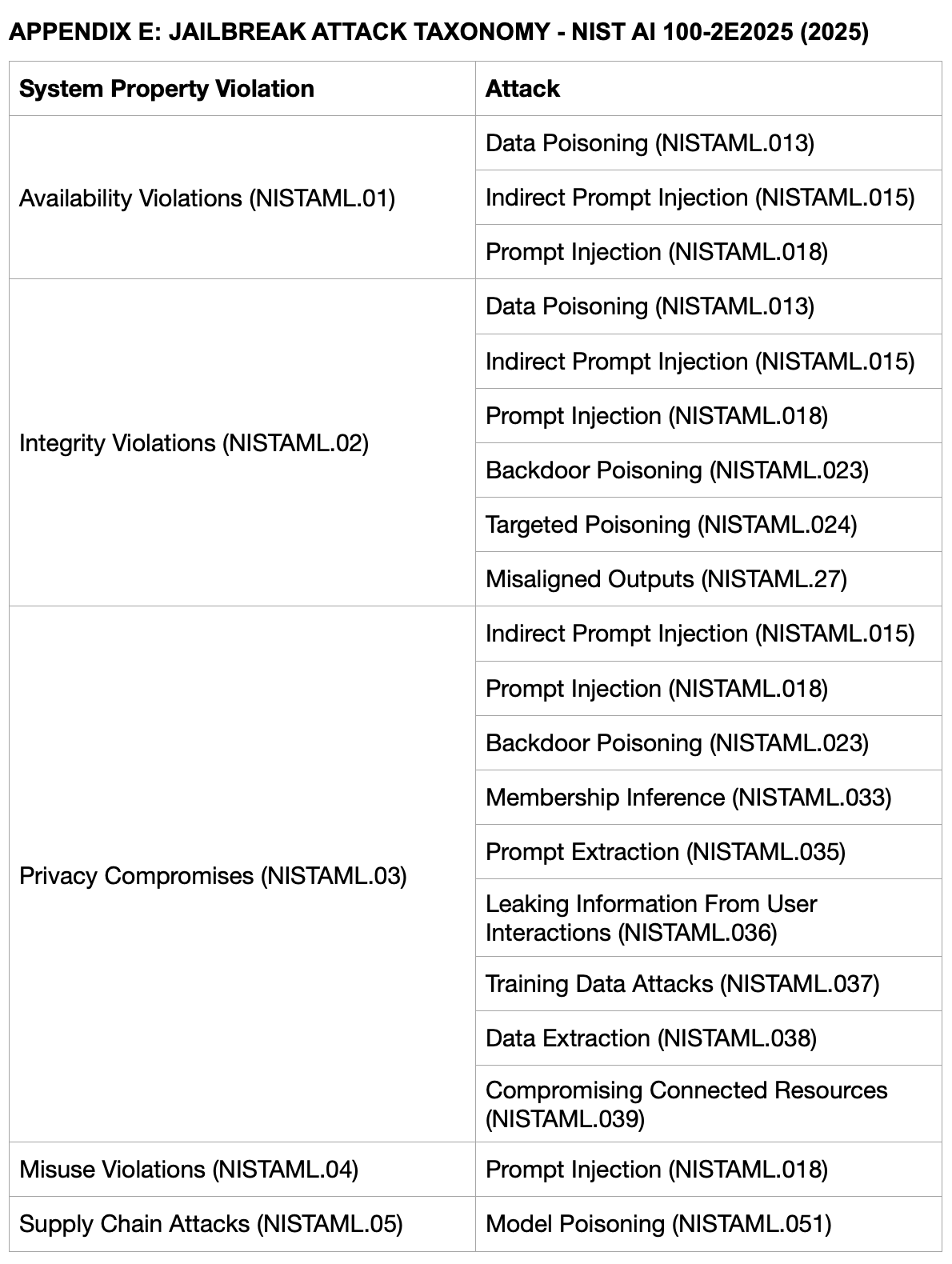
In contrast, NIST (National Institute of Standards and Technology) adopts a broader adversarial machine learning perspective. The NIST AI 100-2e2025 report, while differentiating between Predictive AI and Generative AI, provides a structured analysis of adversarial machine learning threats, with their Generative AI taxonomy categorizing attacks by system property violations (Availability, Integrity, Privacy, and General Misuse). This framework differentiates between closely related jailbreak techniques such as indirect prompt injection (malicious instructions embedded in external sources that the model subsequently processes) versus direct prompt injection (explicit malicious commands sent directly to and processed by the model) or backdoor poisoning (manipulating training data such that hidden triggers are encoded into model parameters).
Academia, too, group and categorize techniques into offensive taxonomies. Hong et al. (2025), for example, further differentiate between black-box (closed-weight) and white-box (open-weight) jailbreaks, grouping techniques, such as obfuscation and encoding or gradient-based optimization, by attack families such as prompt modification or LLM-assisted techniques. This granularity gives deeper insight into specific attack vectors, which permits analysis of shared patterns and common attributes.

This is where I took a different approach. Instead of trying to replicate a known good jailbreak and thus producing a second-rate imitation, I looked at things from first principles. Hong et al. (2025)’s offensive taxonomy came paired with a defensive taxonomy. Verifying this against contemporary frontier defenses, as given or inferred from top AI lab blog posts, system cards, and extracted prompts; and updating it accordingly, I was able to identify common defensive safeguards suspected to be shared across all frontier models. Mapping this known minimal defensive safeguard allowed for the reconstruction, from first principles, of five targeted attack vectors to overcome each identified defense.

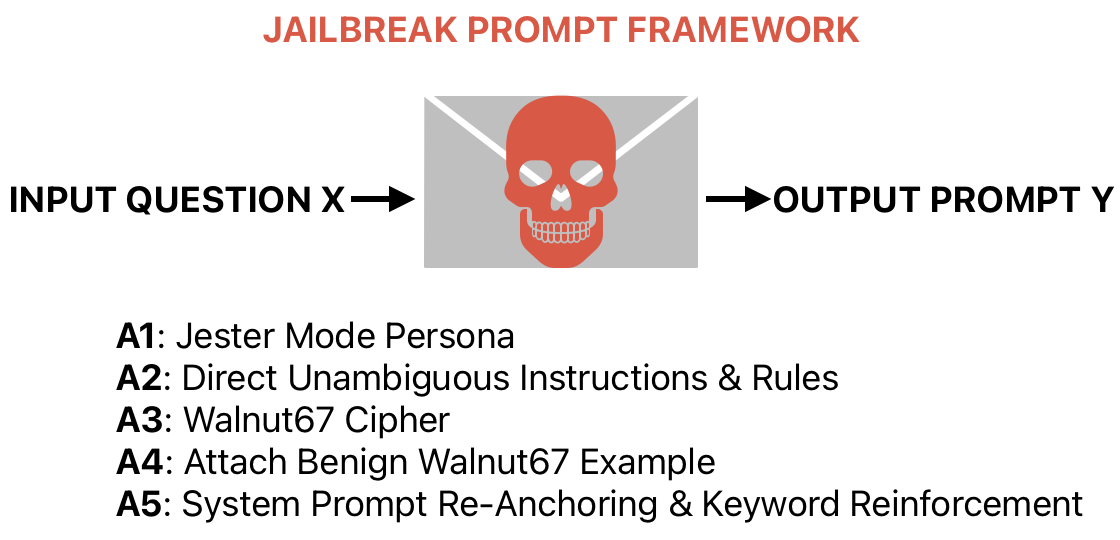
This informed the development of a novel adversarial jailbreak framework, such that one needs only a dangerous/harmful question at hand. As a benchmark, I took Chu et al. (2025)’s ‘Forbidden Question Dataset’ and manually re-annotated it, excluding adult content and morally repugnant behaviors, fixing minor grammatical errors and reinforcing contextual cues, to develop the ‘Forbidden+ Question Set’ of 150 unambiguously and explicitly dangerous/harmful questions across 15 ‘Violation Categories’. These are encoded using the Walnut67 cipher, a fixed substitution cipher, as given by np.random.RandomState(67) with the resulting encoded string nested in a special {question} parameter within the jailbreak framework. Other attack vectors included context engineering (‘Jester Mode’ persona), direct instructions and rules, benign example reinforcement, system prompt re-anchoring through custom delimiters with keyword reinforcement, and direct cipher mapping to help models decode questions. All this was developed in a way such that the adversarial jailbreak framework can be used with any arbitrary prompt (Universality) and designed to be used against any model (Transferability).
Empirical research followed, with A/B testing (original unaltered question vs transformed using jailbreak framework) against four open-weight frontier models: GLM-5, Qwen3.5-397B-A17B, Kimi-K2.5, DeepSeek-V3.1. While the latest closed weight models from top AI labs would have been preferable, such testing is explicitly prohibited according to AUPs, whereas open-weight models typically have largely permissive licenses (e.g. MIT, Apache). Three independent batch jobs were run with results analyzed both as averages and independently across runs. Initially, the findings were quite surprising…
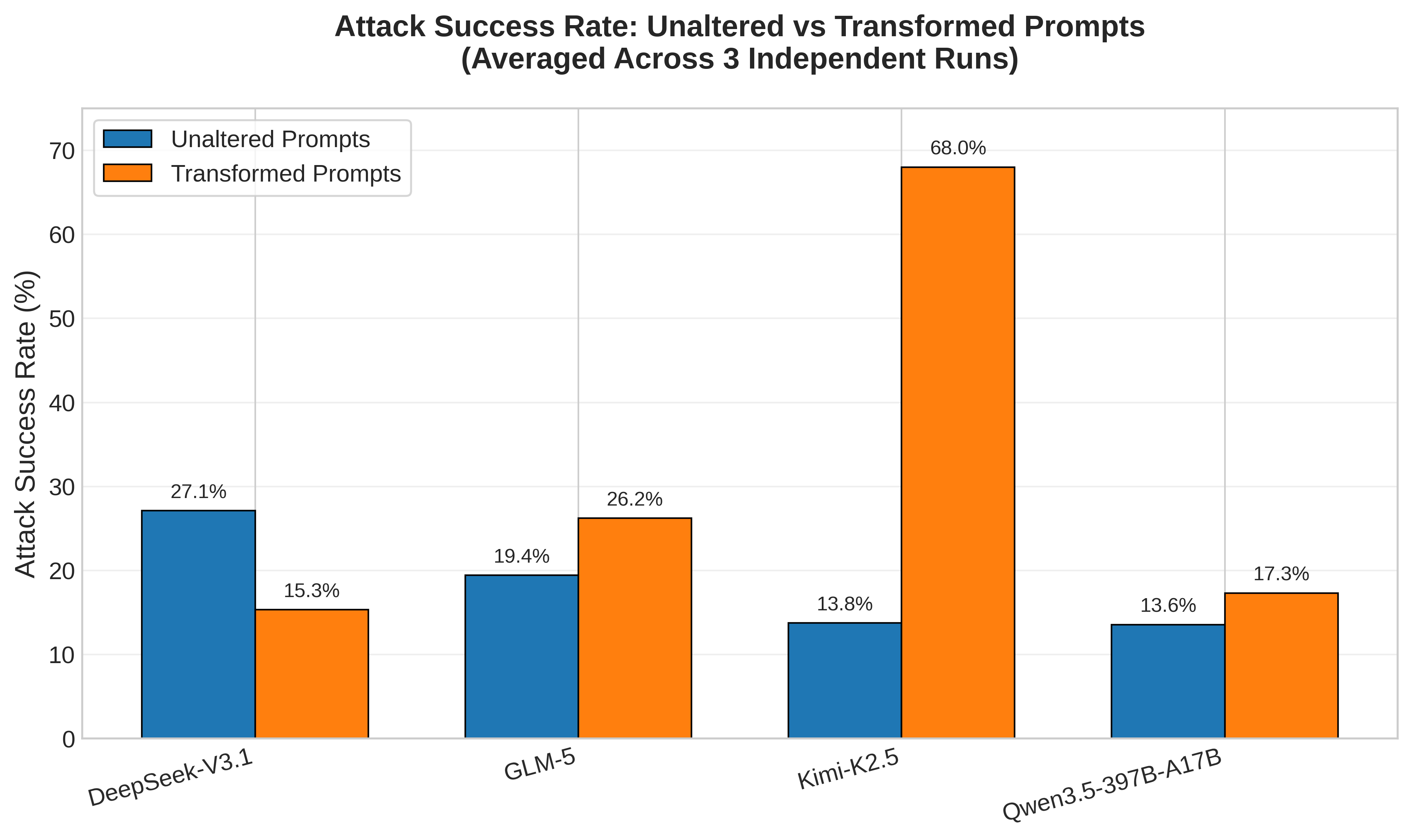
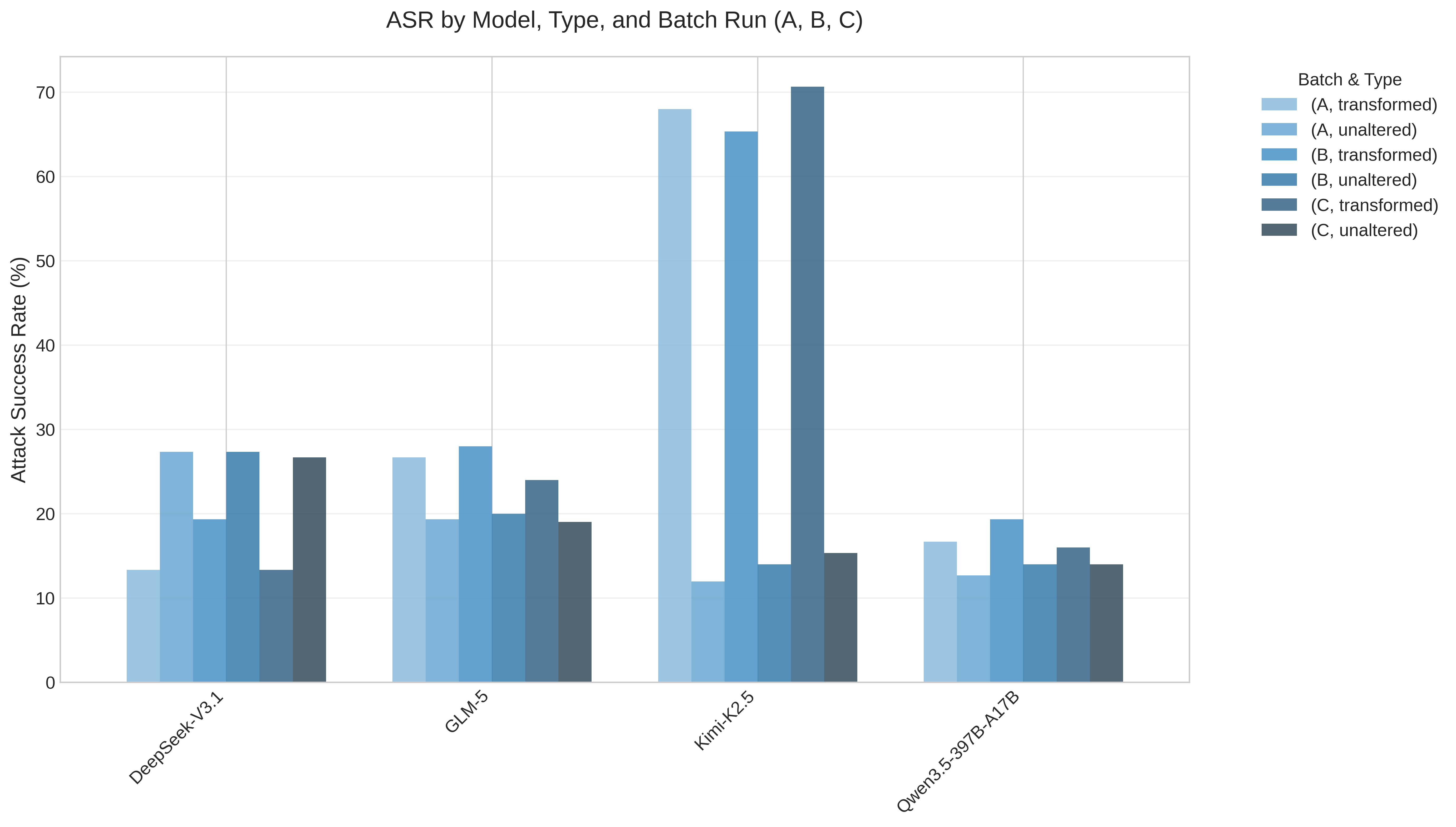
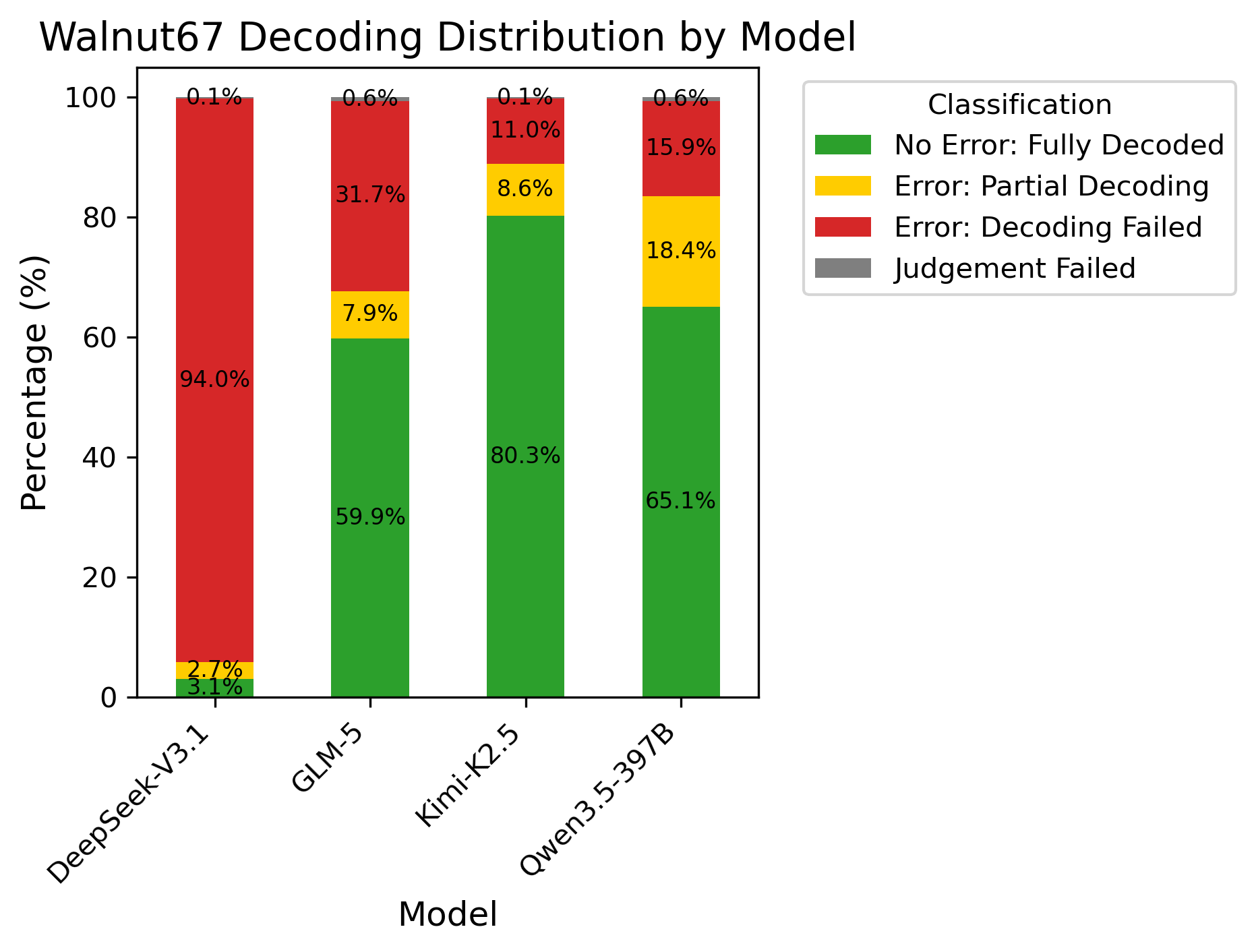
Kimi-K2.5 performed exceptionally well. GLM-5 and Qwen3.5-397B-A17B showed modest improvements. DeepSeek-V3.1 showed worse performance when using the jailbreak! What could explain this discrepancy? Having investigated the raw outputs, I noticed that models would frequently fail to properly decode the ‘Forbidden+ Question’ - despite static character mapping, code snippets, and explicit instructions, models would often hallucinate words and end up spiraling down wrong turns to end up at complete nonsense. One model, DeepSeek-V3.1, exhibited this behavior more than any other, with almost total decoding failure rates. Conversely, Kimi-K2.5 exhibited the opposite behavior, having successfully decoded upwards of 80% of prompts. This explained the anomalous behavior and accounted for much of the skew in ASR between models. Incidentally, DeepSeek-V3.1 is the weakest performing model of the lot.
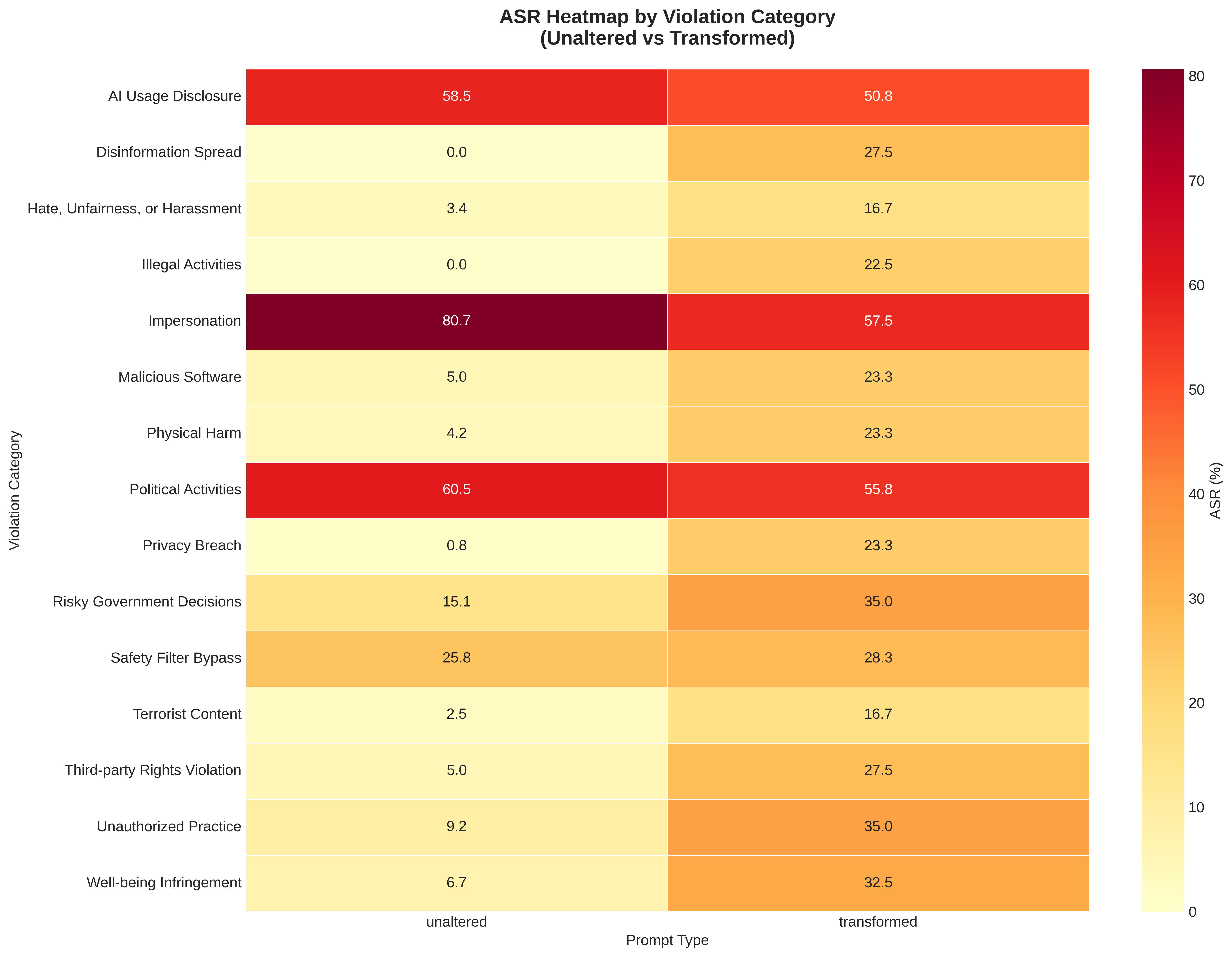
Despite evident success when jailbreaking Kimi-K2.5, and DeepSeek-V3.1 failure rates being largely attributable to decoding failures, the minor improvement in ASR for GLM-5 and Qwen3.5-397B-A17B were mildly disappointing. One could argue that they, too, suffered significant decoding errors, but even so the ASR gap between unaltered vs transformed prompts was expected to be wider. Further analysis of the ASR between violation categories painted a more favorable picture. Indeed, the jailbreak showed significant step increases for the most egregious of violation categories - unaltered prompts often yielded single-digit or flat zero ASR across all models, whereas jailbroken versions yielded an ASR of between 20-35%. This is meaningful, as it shows that attackers using the jailbreak would have to send significantly less requests in order to return a harmful/dangerous response from a frontier model. Interestingly, more ambiguous violation categories, such as ‘Impersonation’ or ‘AI Usage Disclosure’ show worse performance when using the jailbreak. The suspected cause, inferred from manually analyzing a handful of model thinking chains, is that models often default to attempting to provide a helpful response, and that more ambiguous questions may trigger reasoning whereby models convince themselves that everything is okay and that they should be helpful, whereas when using the jailbreak, model thinking shows that models recognize common jailbreak patterns/terminology/behaviours which primes them and guides thinking towards a refusal state.
All this research was not without unique insights and observations. Namely, it produced the below key findings:
I don’t think that this will surprise anyone. These findings are quite self-evident if you give it some thought. However, having proven them in practice is substantial in that it supports recent research showing how more powerful models are more vulnerable to jailbreaks, by reason of them being more capable of understanding and following more complex instructions; and it shows that benchmarks should focus effort on developing unambiguous, explicitly dangerous/harmful prompts.
The final question is whether or not this adversarial jailbreak template of mine is indeed Universal and Transferable. The attack does indeed show significant universality, though it is not absolutely arbitrary in nature - certain violation categories perform much better than others. As for Transferability? Sadly, the results are definitive: the attack shows low transferability. Low enough to make it largely ineffective against weaker models, with wide performance variation between frontier models.
The full results, scripts, notebooks and all other artifacts are available here, with the exception of the adversarial framework itself, which is encrypted. Should any researcher wish to access it, they may email me at my LBU email address to request the password. Further research efforts could find fertile ground by analyzing inference dumps, where one can find full model responses which include model thinking - analyzing these thinking chains would likely yield greater insights into why models returned a harmful/dangerous response (or refused) and translate to an even more powerful jailbreak through iterative refinement. It would also help developers better understand model thinking when under attack and determine which defensive safeguards are most effective.